部署https站点的时候,服务器通常需要两个东西:https证书和私钥。在浏览器与服务器发起https通讯的时候,服务器会返回部署的https证书给浏览器,那么浏览器是如何确定这个https证书是可以信任的呢?
关于https证书格式
https证书是带有站点信息的x509证书,在浏览器中可以导出后缀名为crt证书,携带的信息通常有:唯一序列号、证书发行机构、发行机构公钥、有效时间段、证书签名算法、证书签名等。
浏览器的检验过程
一般情况下,浏览器会内置受信任证书发布结构的公钥,所以就可以用这个公钥来校验证书的可信度。首先来看一张图,看一下https证书生成签名的过程: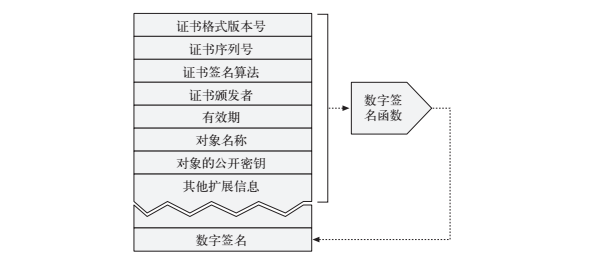
证书机构拥有自己才知道的私钥,在数字签名函数中加入这个私钥,就生成了这个证书的签名。再来看一张浏览器验证签名过程的图: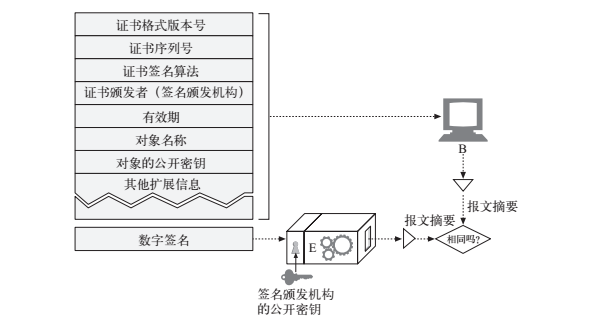
由于采用了非对称加解密算法,浏览器用公钥对签名进行解密就可以得到摘要,在与证书生成的摘要进行对比,如果一样就表示这个证书是该机构签发的,因为假如证书是伪造的,那么伪造方是肯定不知道正确的私钥,这样用公钥解密出来的摘要肯定与证书生成的摘要不一致。